마지막 작성 일시 : 24/06/10
AI ChatGPT, Claude 등 많은 일반인들에게 이제 잘 알려진 서비스입니다.
좀 더 이 분야에 대해서 학습을 하다보면서, 간단한 개발을 하게보면, Hugging Face란 이름을 많이 듣게 됩니다.
그렇다면 Hugging Face는 무엇인지 간단히 정리해 보고, Visual Studio Code에서 이를 간단히 실행해 보는 것을 알아보도록 하겠습니다.
01. 허깅페이스(Hugging Face)란 무엇인가요?
- Hugging Face는 2016년에 설립된 자연어처리(NLP) 분야에서 굉장히 중요한 역할을 하는 오픈소스 기업 및 커뮤니티입니다.
02. 허깅페이스의 역할
- 모델 허브: 사전 훈련된 많은 NLP(자연어처리) 모델들을 공유하고 있습니다. GPT, BERT, RoBERTa 등
- 라이브러리: transformers의 라이브러리의 프로그램은 PyTorch, Tensorflow, JAX 등 다양한 프레임워크에서 최신 NLP모델을 사용할 수 있게 해 줍니다.
- 데이터셋: NLP작업에 필요한 다양한 데이터 셋을 제공합니다.
- 커뮤니티: 연구자, 개발자들이 모델과 데이터셋을 공유하고 협력할 수 있는 플랫폼을 제공합니다.
03. 허깅페이스의 화면 구성
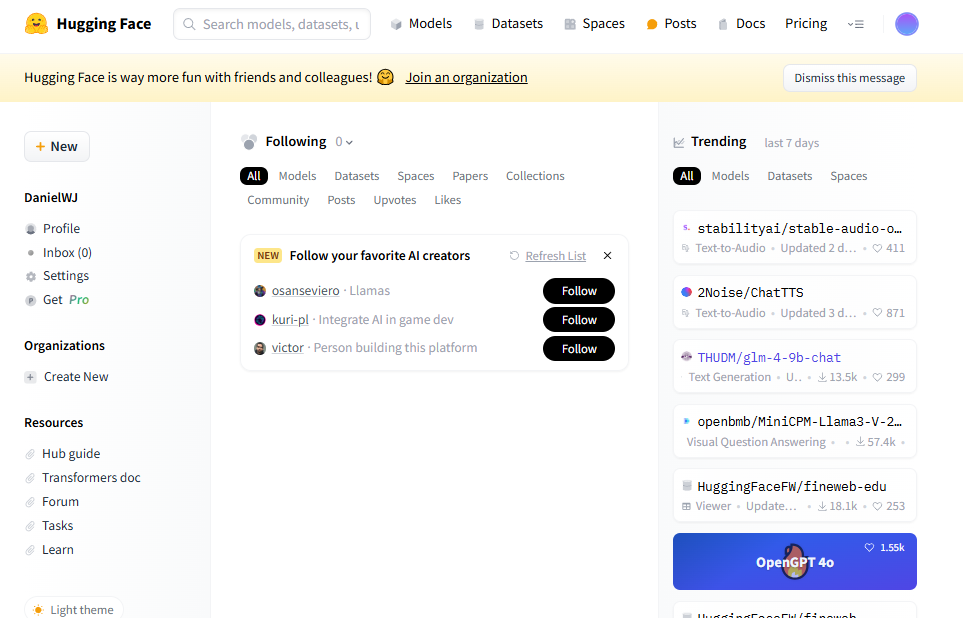
- Models: 다양한 사전 학습 모델 검색 및 사용할 수 있습니다. 모델을 직접 업로드 및 공유 가능합니다.
- Datasets: 머신러닝 모델을 학습하기 위한 다양한 데이터 셋을 찾고, 또한 직접 업로드도 가능합니다.
- Spaces: Hugging Face 커뮤니티가 만든 다양한 애플리케이션 데모를 탐색할 수 있습니다. 여기서 모델의 실제 활용 사례를 확인 가능합니다. 또한 사용자들이 직접 자신의 애플리케이션을 배포하고 호스팅 할 수 있는 환경을 제공합니다. Streamlit, Gradio, Docker 등을 지원
- Posts: Hugging Face 커뮤니티 내에서 사용자들이 작성한 글, 튜토리얼, 노하우 등을 읽을 수 있는 공간입니다.
- Docs: Hugging Face의 다양한 도구와 라이브러리에 대한 문서화된 자료를 제공합니다. 사용법, API 레퍼런스, 튜토리얼 등이 포함되어 있습니다.
- Pricing: Hugging Face의 다양한 서비스와 기능에 대한 가격 정보를 확인할 수 있습니다. 무료 플랜과 유료 플랜의 차이점 등을 확인 가능합니다.
추가 언급 가능한 섹션
- Tasks: NLP, 컴퓨터 비전 등 다양한 분야의 작업별로 최적의 모델과 데이터 셋을 찾을 수 있습니다.
- Organizations: 기업, 연구소, 대학 등의 조직 프로필을 볼 수 있습니다. 조직이 공유한 모델, 데이터셋, 멤버 정보 등을 확인 가능합니다.
Hugging Face는 AI 커뮤니티를 위한 종합 플랫폼으로, 단순히 리소스를 제공하는 것을 넘어 사용자들이 직접 참여하고 기여할 수 있는 환경을 조성하고 있습니다.
04. Hugging Face 기본 예제
Hugging Face를 간단히 사용해 보기 위한 기본 예제를 만들어보겠습니다.
라이브러리는 설치는 prompt에서 진행이 가능합니다. 아래와 같이 pip의 파이썬 명령어를 이용해서 설치가 가능합니다.
단 pip 명령을 이용하기 위해서는 내 컴퓨터에 python이 설치되어 있어야 합니다.
개발 도구로 visual studio code를 이용할 경우는, terminal 창에서 명령어 실행해서 설치를 할 수 있습니다.
A. 라이브러리 설치
pip install transformers
B. 감성 분석 해보기
감성 분석은 텍스트 문장을 보고, 해당 문장안에서 긍정 감정인지, 부정 감정인지 분석하는 것을 말합니다.
from transformers import pipeline
# 감성 분석 파이프라인 생성
sentiment_analyzer = pipeline("sentiment-analysis")
# 분석할 텍스트
texts = ["I love this product!", "This is the worst experience ever.", "The movie was okay."]
# 텍스트 분석
for text in texts:
result = sentiment_analyzer(text)
print(f"Text: {text}")
print(f"Sentiment: {result[0]['label']}, Score: {result[0]['score']:.4f}\n")
코드 설명
- pipeline 함수를 사용해 "sentiment-analysis" 작업을 위한 파이프라인을 생성. 이 함수는 자동으로 적절한 사전 훈련 모델을 다운로드하고 로드합니다.
sentiment_analyzer = pipeline("sentiment-analysis")
- 분석할 텍스트 리스트를 정의
# 분석할 텍스트
texts = ["I love this product!",
"This is the worst experience ever.",
"The movie was okay."]
- 각 텍스트에 대해 감성 분석을 수행합니다. 결과는 'POSITIVE' 또는 'NEGATIVE'이며, 점수는 그 확신도를 나타냅니다.
# 텍스트 분석
for text in texts:
result = sentiment_analyzer(text)
print(f"Text: {text}")
print(f"Sentiment: {result[0]['label']}, Score: {result[0]['score']:.4f}\n")
# 결과 내용
Text: I love this product!
Sentiment: POSITIVE, Score: 0.9999
Text: This is the worst experience ever.
Sentiment: NEGATIVE, Score: 0.9998
Text: The movie was okay.
Sentiment: POSITIVE, Score: 0.9998
기타 감성 분석 이외에도 다음과 같은 작업들을 수행 가능합니다.
텍스트 생성(text-generation), 질문 답변(question-answering), 이름 개체인식 (ner), 텍스트 요약(summarization)
눅 20:38
하나님은 죽은 사람들의 하나님이 아니라 살아 있는 사람들의 하나님이시다. 하나님이 보시기에는 모든 사람이 살아 있는 것이다.
오늘도 좋은 하루, 감사하는 하루가 되시기를 응원합니다.